The Problem
A B2B SaaS startup (henceforth referred to as the Company) had built their platform 4 times in 6 years (that’s an average of a 1 version per 1.5 years). Each time a new version was built, new features and capabilities were baked in, but inevitably, some features and business logic were also lost. There was no cohesive plan from version to version.
Stakeholders were not consulted when features were added or removed. The technical architecture and application code were short-sighted and difficult to extend, leading to technical debt that made building on each the new version slow and error prone. There was a limited REST API only where it was absolutely necessary to hook into an e-commerce workflow.
Additionally, there were key deficiencies and missing capabilities in the current iteration of the platform. There was low data integrity that made it difficult to report, compounded by incomplete or mis-mapped data migrations implementations. Financial transactions could be – and were – altered after the fact, making it difficult or impossible to accurately trace the money trail in some cases. It tried to re-invent the wheel for solved problems like subscription management instead of relying on a tried and true platform. The tech stack was too fractured, and resourcing was becoming difficult and expensive.
The Solution
Proposal
Scrapping a platform entirely and rebuilding it from scratch is very rarely the right course. There is usually a way to chip off pieces of it and replace a vertical stack of functionality little by little to mitigate risk. However, sometimes the current version isn’t built in a modular fashion that would lend itself to this best practice, and replacing it bit by bit would actually be more error-prone and risky. Instead, it was decided the platform had to be rebuilt, but this time in a way that would support long-term growth and better maintainability.
First, I drafted business case that argued for the business value of creating a new version of the platform. I emphasized clear success metrics that would be used to determine whether the promises laid out had been fulfilled by the conclusion of the project. Here is an abbreviated summary of the success metrics outlined:
- Financial vendor is the source of truth for all financial data.
- Financial data is perpetually auditable.
- Marketing and operational communications are delegated to a 3rd party system.
- Reported bugs drop by 75% or more 2 months after launch.
- Feature implementation time drops by 50% or more 2 months after launch. O
- Technology stack is consolidated.
- Future industries / scenarios / localizations are supported.
- Integrations are supported out of the box due to API-first approach.
I collaborated with product and engineering leadership to finalize the success metrics and identify risks to the project, their potential impact, and mitigation strategies. With a solid proposal in hand, we gathered senior leadership to go over it and listen to their concerns. Importantly, I emphasized that the rebuild would not be their opportunity to add additional features, thus blowing out the scope and delaying release through gold-plating. I did, however, caveat that with my desire to still hear their feedback for future consideration even if their ideas wouldn’t be feasible for the MVP release.
Any net new feature not present in v4 at the time of v5 release will not be considered for v5. However, any proposed change to the way we do things in v4 that we want to incorporate into the rebuild will be considered. We will be very disciplined with what we bake into the MVP of v5 because every moment that we are still building v5 represents further risk to the business, and further enhancements that we do in v4 that we will have to redo in v5. Please use the below decision tree as a guide.
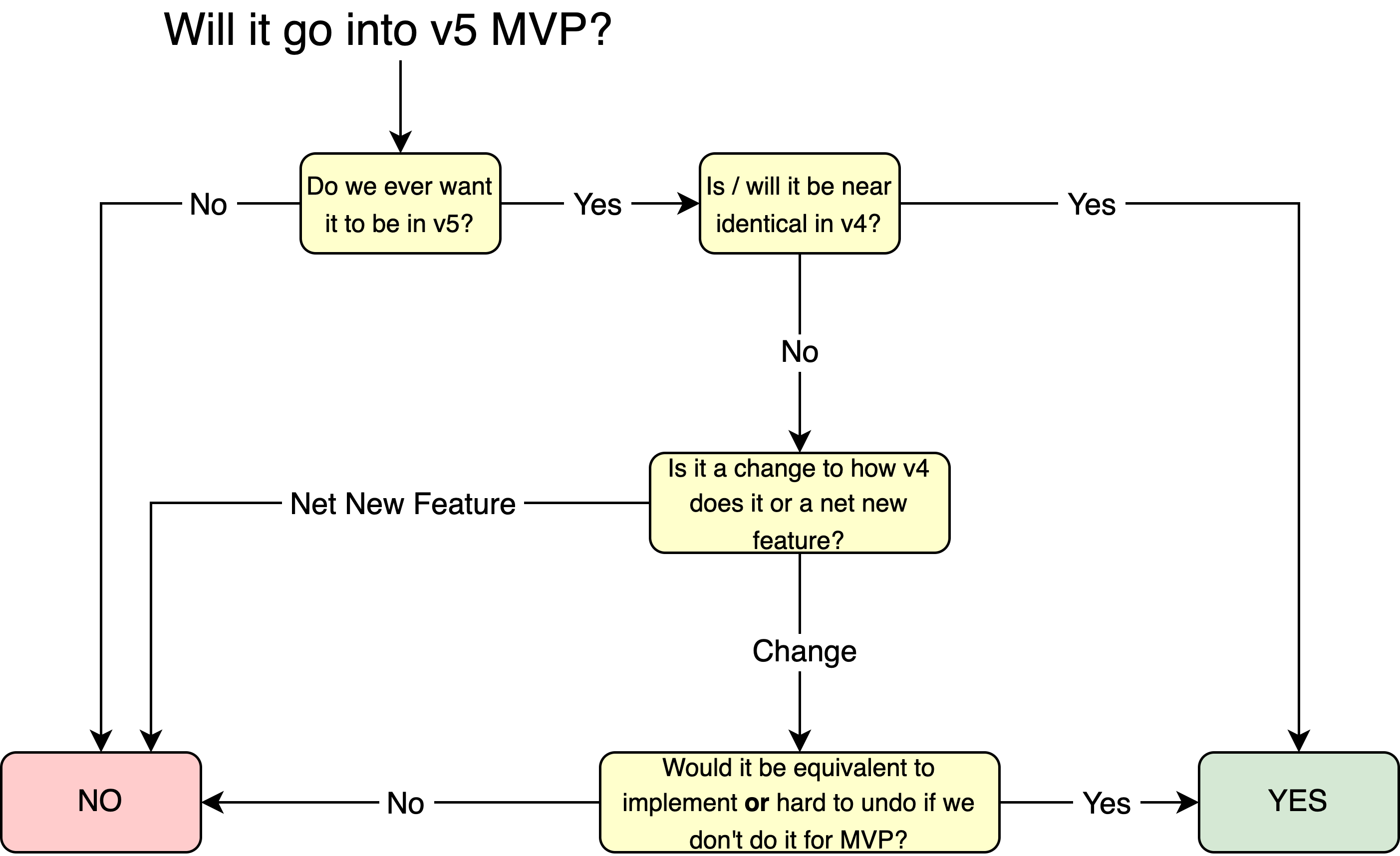
Getting stakeholder buy-in upfront is extremely important for projects of this magnitude. It gives stakeholders the opportunity to voice their concerns and understand the motives and goals of the project. It eliminates the risk of a stakeholder coming back later with claims of not being kept in the loop on important product development matters.
I have witnessed skunkworks teams working in the shadows on big initiatives such as this. Sometimes it pans out, sometimes it doesn’t; it’s a huge risk in terms of stakeholder management either way. I prefer to default to transparency. If you can’t convince leadership of the business value of an initiative, then you don’t have the right to spend company resources to work on it. I took stakeholder management a step even further and created a departmental sign-off sheet for each phase of the project to ensure that there were no surprises at the end of the project.
Strategy
I did an exhaustive audit of the current platform’s functionality. Each persona we served equated to a set of capabilities (permissions). I constructed a user role capability matrix to document everything that users of the current platform were able to do. I then shared the matrix with the engineering team and departmental stakeholders and had them sign off on its completeness from their perspective. I wanted to avoid the same pitfalls that had plagued earlier rebuilds of the platform; there would be no undocumented lost functionality this time around.
Next, I worked with engineering leadership on the broad plan of attack. We discussed each phase in just enough detail to make it estimable and have the broad requirements roughed out. We iterated over dependencies and resourcing scenarios until we finalized a tentative project plan, which I then presented to senior leadership so that they knew what to expect from the product development department in terms of phases and milestones.
Execution
With all stakeholders aligned and a rough plan finalized, we kicked off the project with all product, engineering, and UX team members in attendance. We went over the plan, assigned roles, and got valuable feedback that led to minor adjustments to assumptions we had made.
As the engineering team started to lay the technical foundation for the project, I was busy iterating on wireframes and user flows with our UX designer. Once I was satisfied that we had captured the optimal user paths (guided by the role capabilities matrix), I socialized the wireframes with the engineering team and company leadership and made adjustments based on valuable feedback.
From there, I iterated on each vertical domain within the application with the UX designer to generate high-fidelity mockups. Before each iteration, I met with relevant stakeholders in each area to get their feedback on the how the current platform handled the domain and what the new version could do better – again, being careful not to make any promises that would blow up scope and delay the project’s completion. After I was satisfied with the UX for each area, we synced back up with product and engineering leadership to confirm the results were in line with their expectations.
The Results
This version of the platform will not succumb to the same fate as the 4 before it; this platform will be built to last. The intended functionality, scope, and risks were well-documented at the outset. There will be no complaints of lost features. Stakeholders were informed and involved at every step of the way. The API-first architecture will give us a robust platform to build our UIs, as well as the capability to integrate seamlessly with 3rd parties. The financial data integrity issues will be a thing of the past. No platform is perfect, but refactoring code will be far less risky than previously because the platform was made to be readily extensible, utilizing best practices for architecture and application development.
Using my extensive experience in project management, I led the planning process from A to Z. I kept stakeholders aligned, informed, and involved. I was equally at home in database mapping discussions as I was in discussions about UX design patterns. I kept the trains running on time and saw to it that requirements were ready long before they became a bottleneck for the engineering team implementing them. I worked closely with the engineering team, making tactical adjustments along the way to account for technical and resource constraints. While no project ever goes off without a hitch, we followed best practices and thus ran into fewer surprises than we otherwise would have.